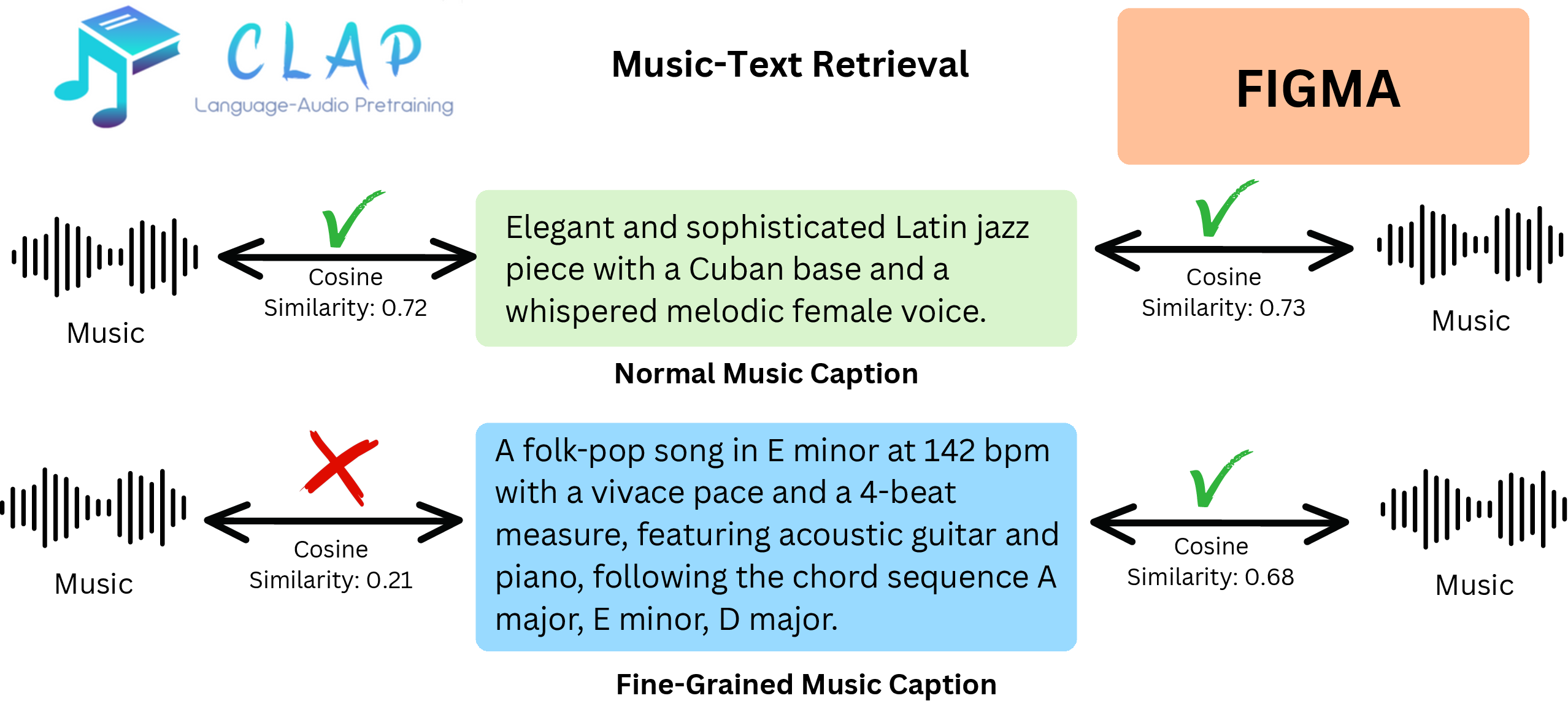
The Problem
Why existing models fail on detailed queries
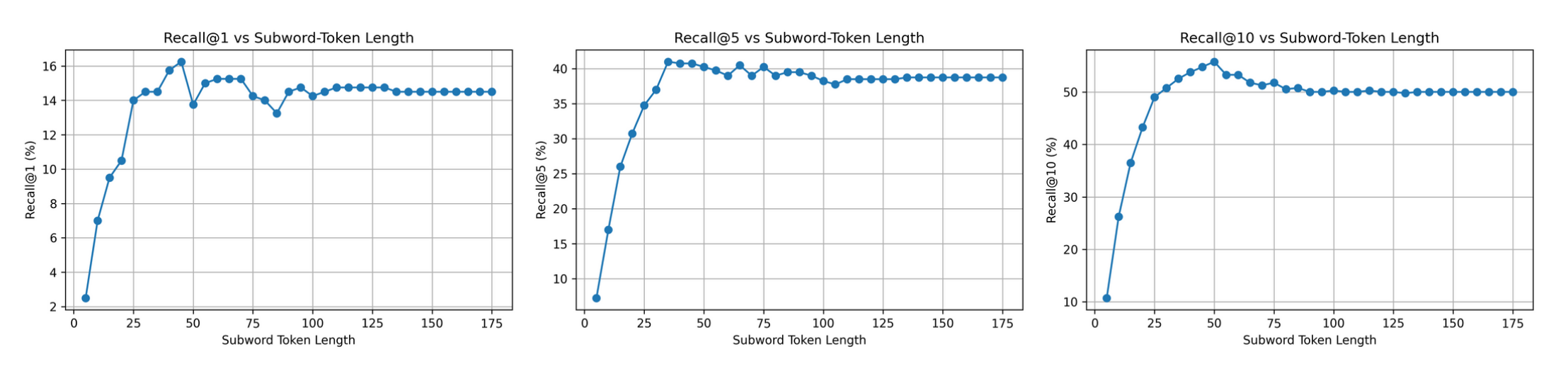
Despite being trained on long, richly detailed captions, CLAP-based models effectively use only the first 40–50 tokens. Everything after—the musical substance—is ignored.
The cause is architectural. Standard models compress audio into a single mean-pooled vector and text into a single [CLS] token before computing similarity. This collapses both modalities, discarding temporal audio structure and token-level text distinctions. Long captions behave like bags of words.
We confirmed this empirically: truncating MusicBench captions to their first 50 tokens produces nearly identical retrieval scores as using the full caption. Further, fine-tuning LAION-CLAP on FGMCaps training data—which has detailed music-theoretic annotations—yields only marginal gains, showing the bottleneck is in the objective, not the data.
Our Approach
Multi-view contrastive alignment
Architecture. We freeze both encoders—MuQ (audio, pretrained self-supervised on music) and Microsoft Multilingual E5 Large (text)—and train only lightweight projection heads (~22M parameters). Each projector is two Transformer encoder layers + a linear map into a shared 512-d space, applied separately to both global pooled and full-sequence features.
Frame-level loss. For each audio frame, we find the maximally similar caption token, average these per-frame scores, and apply InfoNCE. Paired clips are positives; all others in the batch are negatives. This encourages grounding of tempo in rhythm tokens, key in harmony tokens, and so on.
Multi-view loss. Global and frame-level objectives are weighted by α = 0.6:
\[\mathcal{L}_{\mathrm{Multi\text{-}View}} = \alpha\,\mathcal{L}_{\mathrm{global}} + (1-\alpha)\,\mathcal{L}_{\mathrm{frame}}\]
Training. 15 epochs, batch size 256, Adam at 1×10⁻⁴, temperature τ = 0.07, early stopping on validation Recall@1.

Dataset
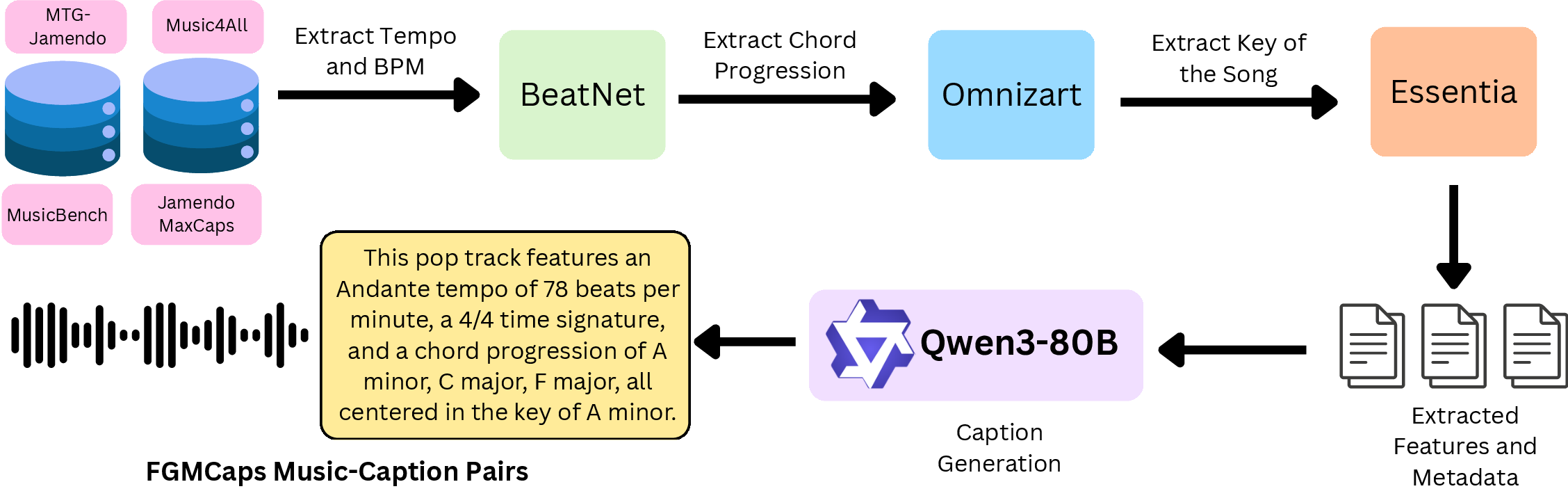
FGMCaps — 380K annotated music–caption pairs
The first large-scale dataset combining music-theoretic annotations—chord, tempo, key, beat—with natural language captions at scale.
Audio is drawn from four public sources (MTG-Jamendo, Music4All, JamendoMaxCaps, MusicBench). Musical attributes are extracted automatically: BeatNet for tempo and beat count, Omnizart for chord progressions, Essentia's KeyExtractor for key and mode. Captions are generated by Qwen3-Next-80B-A3B-Instruct from structured attribute prompts with randomized attribute order to avoid position bias. Stratified splitting ensures no data leakage between train / validation / test.
| Dataset | # Train / Test | Chord | Tempo | Beat | Key | Captions |
|---|---|---|---|---|---|---|
| JamendoMaxCaps | 189,515 / 0 | ✗ | ✗ | ✗ | ✗ | ✗ |
| Music4All | 108,042 / 0 | ✗ | ✓ | ✗ | ✓ | ✗ |
| MusicCaps | 5,521 / 0 | ✗ | ✗ | ✗ | ✗ | ✓ |
| MusicBench | 52,768 / 400 | ✓ | ✓ | ✓ | ✓ | ✓ |
| FGMCaps (ours) | 380,878 / 10,000 | ✓ | ✓ | ✓ | ✓ | ✓ |
FGMCaps is the only dataset at this scale combining all four music-theoretic attributes with natural-language captions.
Experiments & Results
State-of-the-art across all benchmarks
FIGMA is evaluated against 10+ baselines including all LAION-CLAP variants, MS-CLAP, MuQ-MuLaN, M2D-CLAP, and CLAMP 3. On MusicBench, FIGMA reaches 34.52% T2A R@1—a 21.4% relative gain over the previous best (CLAMP 3). The gains are larger on the harder, out-of-domain FMACaps-Eval benchmark (1,000 pairs from Free Music Archive), where FIGMA achieves a 73.3% relative improvement. On the in-distribution FGMCaps test set, FIGMA reaches 26.15% T2A R@1 while the best baseline manages only 2.22%.
MusicBench
| Model | Text-to-Audio | Audio-to-Text | ||||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@20 | R@1 | R@5 | R@10 | R@20 | |
| LAION-CLAP (Music) | 25.38 | 55.84 | 68.53 | 79.70 | 25.38 | 61.93 | 76.14 | 89.34 |
| MuQ-MuLaN | 20.81 | 47.71 | 62.94 | 74.62 | 17.76 | 43.65 | 57.86 | 78.68 |
| M2D-CLAP | 25.38 | 55.33 | 70.05 | 78.17 | 36.55 | 63.96 | 75.63 | 84.77 |
| CLAMP 3 | 28.43 | 57.87 | 74.62 | 89.85 | 5.08 | 24.37 | 34.01 | 52.28 |
| FIGMA | 34.52 | 65.99 | 81.73 | 91.37 | 39.09 | 68.02 | 80.71 | 88.83 |
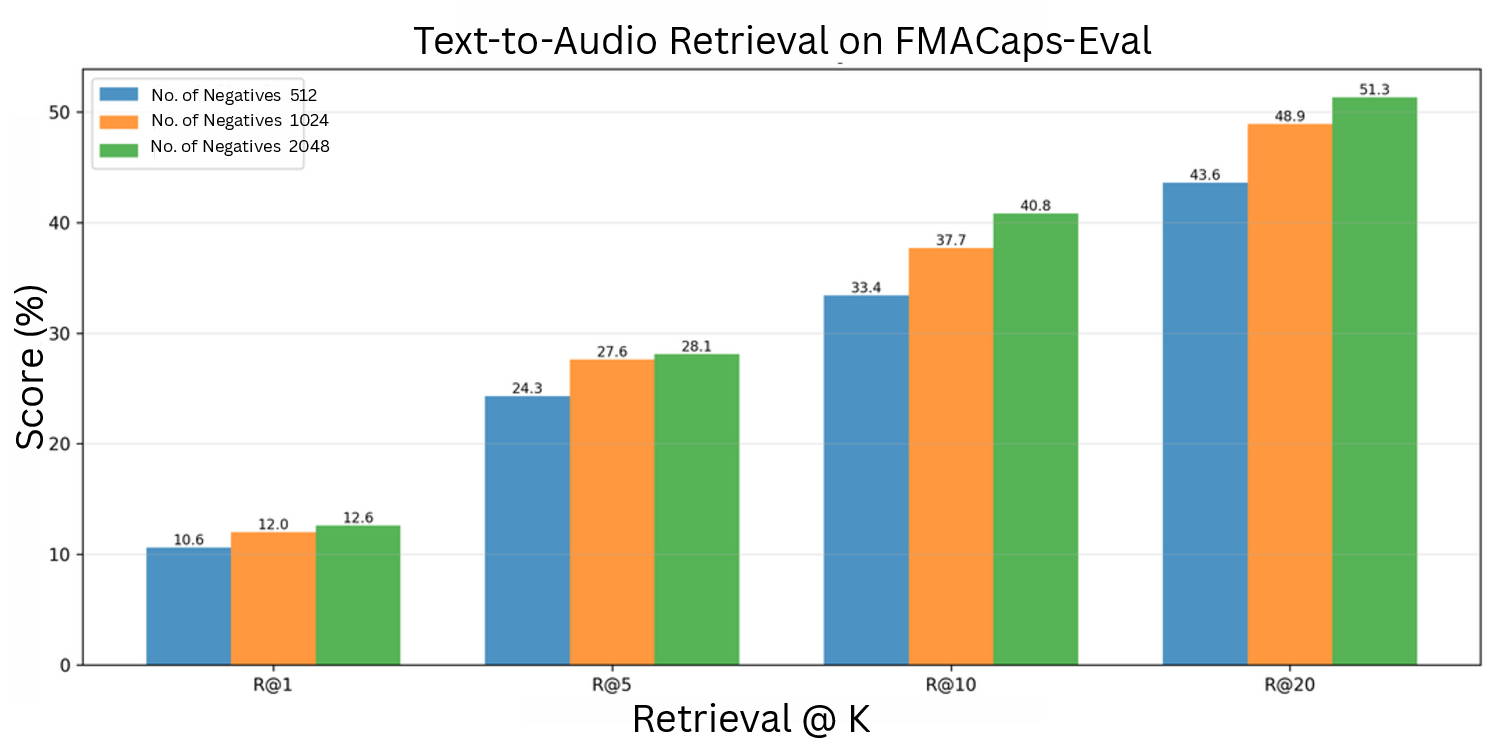
FMACaps-Eval (out-of-domain)
| Model | Text-to-Audio | Audio-to-Text | ||||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@20 | R@1 | R@5 | R@10 | R@20 | |
| LAION-CLAP (Music) | 2.60 | 9.40 | 14.80 | 21.60 | 3.00 | 11.60 | 18.50 | 28.10 |
| MuQ-MuLaN | 4.10 | 12.40 | 17.80 | 27.50 | 3.90 | 11.70 | 19.10 | 28.10 |
| M2D-CLAP | 1.90 | 6.70 | 11.40 | 17.80 | 3.30 | 11.90 | 19.70 | 30.80 |
| CLAMP 3 | 7.50 | 20.70 | 30.80 | 43.10 | 1.10 | 4.10 | 6.40 | 11.70 |
| FIGMA | 13.00 | 28.00 | 37.60 | 48.60 | 13.20 | 33.30 | 42.90 | 53.40 |
Best in bold (red); second-best underlined. Full 11-model comparison including all LAION-CLAP and MS-CLAP variants in the paper.
Robustness to attribute perturbations
To verify FIGMA genuinely encodes fine-grained attributes—not just surface-level patterns—we construct hard-negative queries from 3K test clips by altering one attribute at a time: key, BPM, tempo marking, beat count, or chord sequence. FIGMA maintains 34–43% A2T R@1 under targeted perturbations, confirming representations are grounded in specific musical properties rather than holistic semantics.
Takeaway
A new paradigm for music retrieval
Fine-grained music retrieval requires aligning specific audio moments to specific text tokens—not just global embeddings. FIGMA demonstrates that a frame-level, token-wise contrastive objective atop frozen encoders is sufficient to unlock the musical information already present in rich captions. Paired with FGMCaps—the first dataset systematically combining chord, tempo, beat, and key annotations at scale—FIGMA sets a new state of the art across in-domain and out-of-domain benchmarks while remaining compute-efficient (~22M trainable parameters). We hope both the model and dataset serve as a foundation for future work on fine-grained audio understanding and precision music search.